sticker: emoji//1f995🦕
🦕
2주차 활동 내용
2주차 목표
- 각자 맡은 음성 패턴 인식 파트 공부하기
활동결과
- 화자분할(Speaker Diarization): 두 사람 이상이 대화를 하는 경우 각 화자를 구분하는 기술로, 화자가 다르다는 것을 인식하기 위한 기술이다.
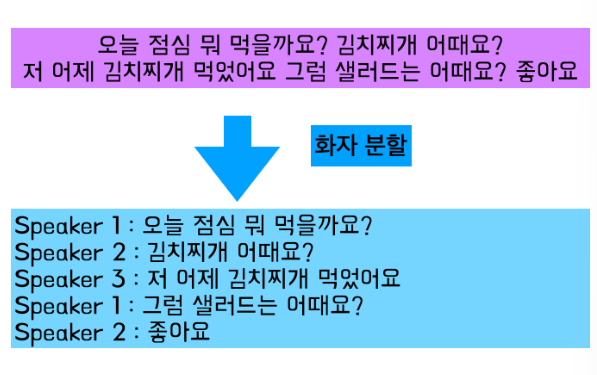
화자 분할 과정
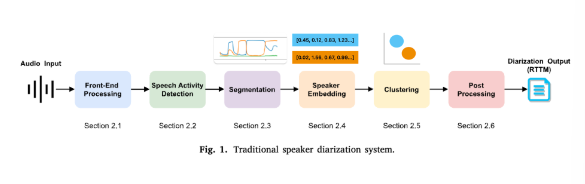
- Front-End Processing
음성 향상 / 잡음 / 반향 제거 등의 전처리를 수행하며
중첩되는 음성 영역을 각각 분리한다. (Speech separation) - Speech Activity Detection
= voice activity detection (VAD 라고 더 많이 사용한다고 함)
실제 음성과 배경 소음(noise)을 구분하여 실제 음성을 얻는다. - Segmentation (음성 분할)
입력 오디오 스트림을 여러 세그먼트로 나누어 화자 균일 세그먼트를 얻는다.
아래 예시 그림의 경우, 3명의 화자의 음성을 균일하게 나눈 것이다.
- Speaker Embedding
각 세그먼트의 임베딩을 구한다. 예) i-vector, DNN-based embeddings… - Clustering
각각의 임베딩 값을 k개의 클러스터로 레이블링 한다.
화자 분할의 경우 다음 2가지 클러스터링 방법을 이용한다.- Agglomerative hierarchical clustering (AHC)
- Spectral clustering
- Post Processing
최종적으로 결과를 더 잘 나타내기 위해 다시 한번 정제하는 과정이다.
이 과정을 마치면 화자 분할의 공식 포맷인 'RTTM' 포맷에 맞춰 화자 분할 정보를 출력하는데, 이 RTTM 파일로부터 '누가 언제부터 언제까지 말했는가' 를 알 수 있다.

Interactive Graph
Table Of Contents